使用 Xpath 定位元素
什么是 Xpath
XPath (XML Path Language) 是一门在 XML 文档中查找信息的语言,可用来在 XML 文档中对元素和属性进行遍历。
XPath 定位在爬虫和自动化测试中都比较常用,通过使用路径表达式来选取 XML 文档中的节点或者节点集,熟练掌握 XPath 可以极大提高提取数据的效率。
因为 XPath 解析数据,是基于元素(Element)的树形结构,所以学习 XPath 前,先了解一下 html 的结构及常用标签。
基本标签
1 | 标题:`<h1>、<h2>、<h3>、<h4>、<h5>、<h6>、<title>` |
XPath 表达式学习
常用表达式
| 表达式 | 描述 |
|---|---|
| nodename | 选取次节点的所有子节点 |
| / | 从根节点开始选取,绝对定位 |
| // | 从符合条件的元素开始,不考虑他们的位置,相对定位 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 通过属性选取 |
XPath 常用的定位方式:
1. 元素属性,快速定位,唯一属性: //*[@id="images"]
2. 层级与属性结合,解决没有属性问题://div[@id="images"]/a[1]
3. 属性与逻辑结合,解决多个属性重名问题:
1 | //*[@id="su" and @class="bg s_btn"] |
注意,表达式里的下标是从 1 开始的。
绝对定位以 / 开头,依赖页面的元素的顺序和位置,相对定位以 // 开头,不依赖页面元素顺序和位置,根据条件进行匹配,优先使用相对定位。
学习 XPath 本质就是掌握各种表达式的技巧,除了上述说到方法外,还有一些特别的定位方式:
4. 查找 id 属性的值包含”kw”的元素: //*[contains(@id,'kw')]
5. 查找⽂本⾥包含”新闻”的元素: //*[contains(text(),' 新闻 ')]
6. 查找 class 属性中开始位置包含’s_form_wrapper’关键字的元素:
1 | //*[starts-with(@class,'s_form_wrapper')] |
7. 使⽤多个相对路径去定位⼀个元素⽤// 分开:
//div[@class=‘formgroup’]//input[@id=‘user-message’]
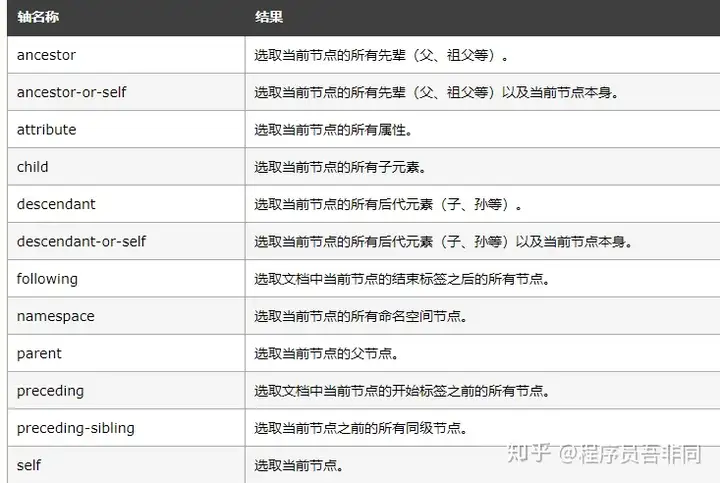
8. 轴定位:
轴定位,使用:: 表示
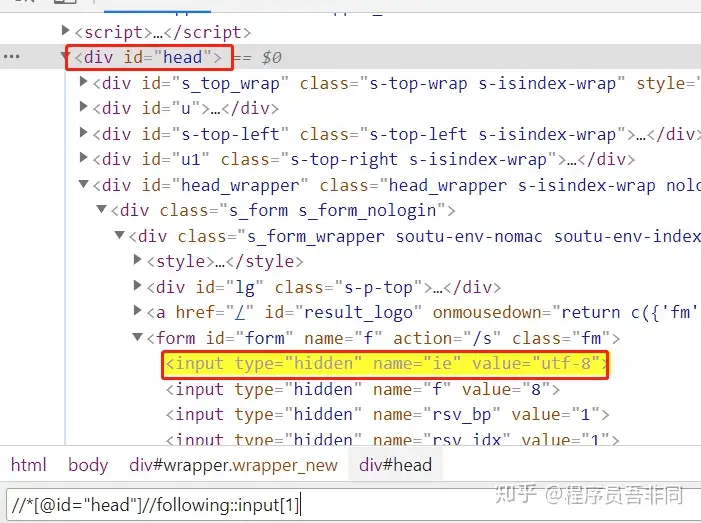
查找 id=”head”元素后⾯标签名为 input 的第一个元素
1 | //*[@id="head"]//following::input[1] |
如何在浏览器中查找和验证 XPath?
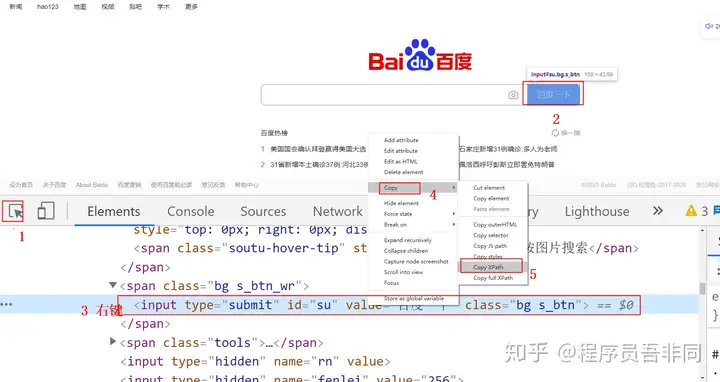
1. 使用 Chrome 浏览器的开发者工具,可以快速获取 XPath 表达式:
点击选择光标,选择页面上的元素位置,在控制台右键选择 Copy XPath,表达式就复制到粘贴板中了。
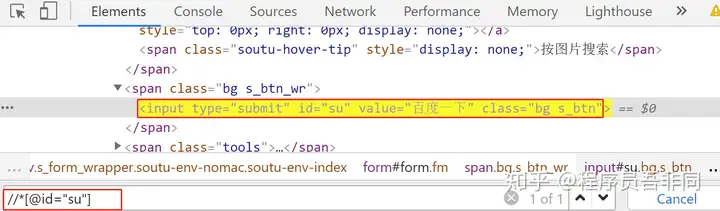
获取到的 XPath 路径://*[@id="su"]
获取 full XPath:/html/body/div[1]/div[1]/div[5]/div/div/form/span[2]/input
2. 验证表达式:
按键“Ctrl+F”,在控制台中输入需要检查的 XPath 路径,对应的元素会有的颜色标识。